The bq command line tool is part of Google Cloud SDK and is used for interacting with Google BigQuery. We can use it to manage BigQuery resources such as datasets, tables, jobs, and queries from the command line.
- Initialize bq tool
- Create resources such as datasets, tables, or views
- Add a file to your project
- Copy a table or data between tables
- List resources such as projects, datasets, tables, or jobs
- Display details of a table
- Execute a SQL query
- Load data from Google Cloud Storage into BigQuery
- Export data from BigQuery to Google Cloud Storage
- Delete resources such as datasets, tables, or views
Initialize bq tool
bq init
This command initializes the bq tool by authenticating the user and setting up the default project.
###@cloudshell:~ (instruction-415216)$ bq init It looks like you are trying to run "/usr/bin/../lib/google-cloud-sdk/bin/bootstrapping/bq.py init". The "init" command is no longer needed with Google Cloud CLI. To authenticate, run gcloud auth. Really run this command? (y/N) y Welcome to BigQuery! This script will walk you through the process of initializing your .bigqueryrc configuration file. First, we need to set up your credentials if they do not already exist. Setting project_id instruction-415216 as the default. BigQuery configuration complete! Type "bq" to get started.
Create resources such as datasets, tables, or views
bq mk dataset dataset_id: Creates a datasetbq mk --table dataset_id.table_id schema.json: Creates a table with a specified schema
# create a dataset called new_dataset ###@cloudshell:~ (instruction-415216)$ bq mk new_dataset Dataset 'instruction-415216:new_dataset' successfully created. # create a table called new_table ###@cloudshell:~ (instruction-415216)$ bq mk --table new_dataset.new_table Table 'instruction-415216:new_dataset.new_table' successfully created.
Add a file to your project
curl -LO [url]For example, I want to add a file from http://www.ssa.gov/OACT/babynames/names.zip and load it into BigQuery. The new dataset called babynames.
# create a new dataset called babynames
bq mk babynames
# add a file to my project
curl -LO http://www.ssa.gov/OACT/babynames/names.zip
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 7232k 100 7232k 0 0 19.0M 0 --:--:-- --:--:-- --:--:-- 19.0M
# unzip file
unzip names.zip
#The bq load command creates or updates a table and loads data in a single step.
bq load babynames.names2022 yob2022.txt name:string,gender:string,count:integer
Upload complete.
Waiting on bqjob_r4b51bf84c2814453_0000018e70e00ae6_1 ... (1s) Current status: DONE
Copy a table or data between tables
For example, I want to copy the table names2022 to the table new_table. The two tables belong to different datasets.
The source table is names2022 and the destination table is new_table. To copy tables, we need to declare the full address of the source and destination tables.
bq cp project_id:dataset_id.source_table_id project_id:dataset_id.destination_table_id
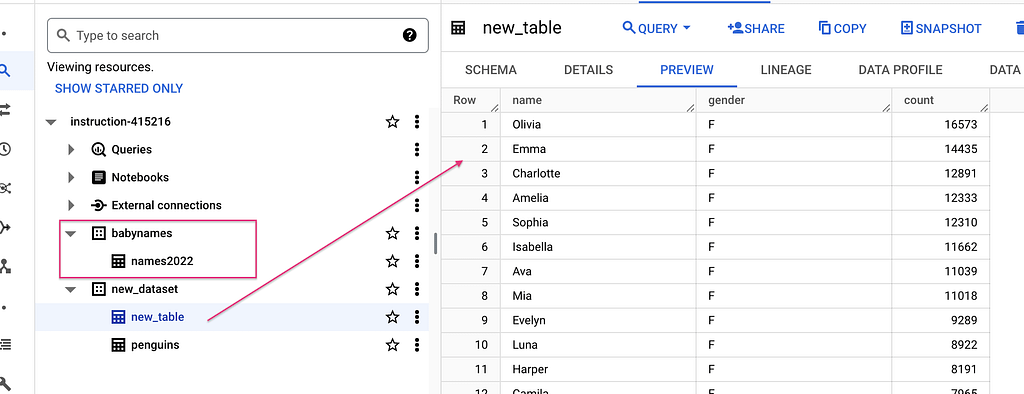
bq cp instruction-415216:babynames.names2022 instruction-415216:new_dataset.new_table Waiting on bqjob_r10fd005afbad0ef8_0000018e70e40df0_1 ... (0s) Current status: DONE Table 'instruction-415216:babynames.names2022' successfully copied to 'instruction-415216:new_dataset.new_table'
List resources such as projects, datasets, tables, or jobs
bq ls #List all the datasets in your project
bq ls project_id # Lists datasets in a specific project
bq ls project_id:dataset_id #Lists tables in a specific dataset#list all the datasets in your project
bq ls
datasetId
-------------
babynames
new_dataset
# list all the datasets in the public dataset
bq ls bigquery-public-data:
datasetId
------------------------------------------
america_health_rankings
austin_311
austin_bikeshare
austin_crime
austin_incidents
austin_waste
baseball
bbc_news
bigqueryml_ncaa
bitcoin_blockchain
blackhole_database
blockchain_analytics_ethereum_mainnet_us
bls
bls_qcew
breathe
broadstreet_adi
catalonian_mobile_coverage
catalonian_mobile_coverage_eu
census_bureau_acs
census_bureau_construction
census_bureau_international
census_bureau_usa
census_opportunity_atlas
census_utility
cfpb_complaints
chicago_crime
chicago_taxi_trips
clemson_dice
cloud_storage_geo_index
cms_codes
cms_medicare
cms_synthetic_patient_data_omop
country_codes
covid19_aha
covid19_covidtracking
covid19_ecdc
covid19_ecdc_eu
covid19_genome_sequence
covid19_geotab_mobility_impact
covid19_geotab_mobility_impact_eu
covid19_google_mobility
covid19_google_mobility_eu
covid19_govt_response
covid19_italy
covid19_italy_eu
covid19_jhu_csse
covid19_jhu_csse_eu
covid19_nyt
covid19_open_data
covid19_open_data_eu
# list all tables in the dataset
bq ls instruction-415216:new_dataset
tableId Type Labels Time Partitioning Clustered Fields
------------ ------- -------- ------------------- ------------------
new_table TABLE
penguins TABLE
Display details of a table
bq show project_id:dataset_id.table_idI want to show the details of a table called shakespeare in a dataset called samples that stored in the public dataset
bq show bigquery-public-data:samples.shakespeare
Table bigquery-public-data:samples.shakespeare
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- ------------------------------------ ------------ ------------- ------------ ------------------- ------------------ --------------------- ---------------------- --------
14 Mar 17:16:45 |- word: string (required) 164656 6432064 6432064 485656
|- word_count: integer (required)
|- corpus: string (required)
|- corpus_date: integer (required)
I want to show the details of a table called penguins in a dataset called new_dataset that stored in my project.
bq show instruction-415216:new_dataset.penguins
Table instruction-415216:new_dataset.penguins
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- ------------------------------- ------------ ------------- ------------ ------------------- ------------------ --------------------- ---------------------- --------
24 Mar 14:04:53 |- species: string 344 19012 19012 5080
|- island: string
|- bill_length_mm: float
|- bill_depth_mm: float
|- flipper_length_mm: integer
|- body_mass_g: integer
|- sex: string
I want to show only schema of babyname’s table.
bq show dataset_id.table_idbq show babynames.names2022
Table instruction-415216:babynames.names2022
Last modified Schema Total Rows Total Bytes Expiration Time Partitioning Clustered Fields Total Logical Bytes Total Physical Bytes Labels
----------------- ------------------- ------------ ------------- ------------ ------------------- ------------------ --------------------- ---------------------- --------
24 Mar 14:31:58 |- name: string 31915 608048 608048 165912
|- gender: string
|- count: integer
Execute a SQL query
You can execute SQL query in the command line. You can use the legacy SQL and the standard SQL. For example, I want to use the standard SQL statement to find out how many “thee” words in the shakespeare table. The result is 42.
bq query --use_legacy_sql=false \ 'SELECT Count(word) FROM `bigquery-public-data`.samples.shakespeare WHERE word = "thee"' +-----+ | f0_ | +-----+ | 42 | +-----+
Another example: I want to the top 5 popular female names in 2022
bq query --use_legacy_sql=false \ 'SELECT * FROM `instruction-415216.babynames.names2022` WHERE gender = "F" ORDER BY count DESC LIMIT 5' +-----------+--------+-------+ | name | gender | count | +-----------+--------+-------+ | Olivia | F | 16573 | | Emma | F | 14435 | | Charlotte | F | 12891 | | Amelia | F | 12333 | | Sophia | F | 12310 | +-----------+--------+-------+
Load data from Google Cloud Storage into BigQuery
bq --location=location load \ # specify the location
--source_format=format \ # specify the the data format
dataset.table \ # specify the destination
path_to_source \ # specify the source
schema # specify the table schema
The schema can be a local JSON file, or it can be typed inline as part of the command. You can also use the --autodetect flag instead of supplying a schema definition.
Export data from BigQuery to Google Cloud Storage
bq extract --location=location \ # specify the location
--destination_format format \ # specify the data format, e.g. CSV,JSON,PARQUET
--compression compression_type \ # specify the compression type
--field_delimiter delimiter \ # specify the boundary between columns in CSV
--print_header=boolean \ # specify whether the data format supports headers, the default mode is true
project_id:dataset.table \
gs://bucket/filename # specify the destination in GCSDelete resources such as datasets, tables, or views
bq rm -r -f dataset_id
This command will delete a dataset and all its tables recursively. For example, if I want to delete the whole dataset called new_dataset, I can simply use bq rm -r -f new_dataset. Then all the resources in the dataset will be deleted.