Introduction
The application aims to streamline the daily tasks of data analysts and data scientists by automating the labor-intensive process of data cleansing, which typically accounts for up to 60% of their project time. It accommodates data in CSV, XLSX, and JSON formats, the most prevalent in data science fields. The tool identifies and handles missing values, eliminates duplicates, converts date and time columns to datetime format, and standardizes spelling to lowercase. Upon completion, users can conveniently visualize and download the processed data.
Key Features
- Support Multiple formats dataset
- Detect Missing values and duplicate records
- Detect and convert date and time look-like data to
datetimeformat - Lowercase the header of dataset
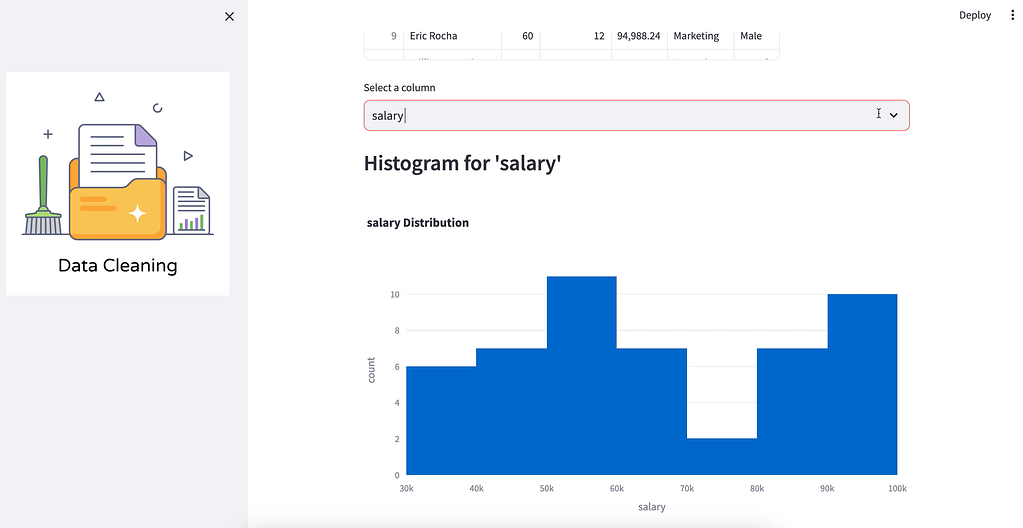
- Allow users to visualize the processed data
- Allow users to download the processed data in CSV format
Tech Stacks
- Python
- Apache Spark
- Streamlit
Integration
This application offers seamless deployment options across leading cloud platforms such as Azure, Google Cloud Platform (GCP), and Amazon Web Services (AWS). Its integration with event-driven functions marks a significant advancement in data cleansing, streamlining the process with intelligent automation. For instance, when new data is uploaded and stored, the application will be triggered by the event and start the cleaning procedure and then store the processed data on the cloud for the downstream tasks.