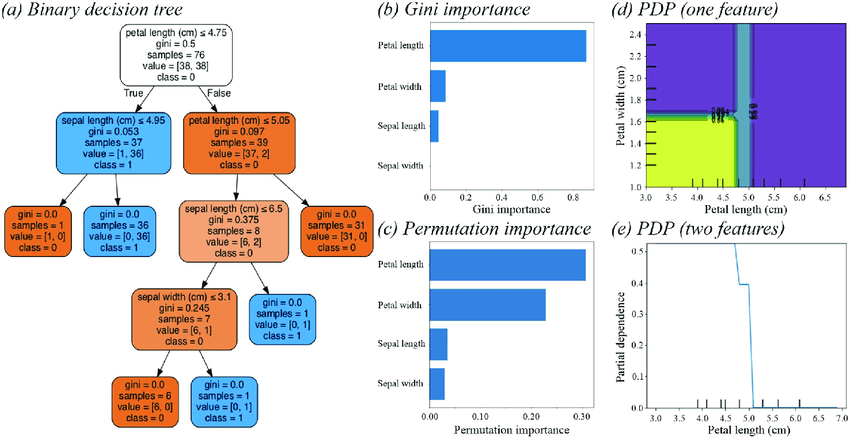
Feature importance refers to the measure of the impact or influence that individual features (also known as variables or attributes) have on the predictions made by a machine learning model. This means it helps us understand which features are the most relevant or significant in determining the output of the model.
Unlocking the secrets of feature importance is an essential quest for machine learning enthusiasts, as it holds the key to unraveling the hidden powers behind a model’s predictions and empowers us to make smarter choices and blaze a trail toward data-driven brilliance.
Interpretability
Feature importance allows us to interpret the model’s behavior and gain insights into what drives its predictions. This is especially important when the model’s decisions have real-world consequences and need to be explained to stakeholders or users.
Example:
Imagine the bank’s loan approval committee is using this model to make critical decisions about loan applications. However, they need to understand why certain applications get rejected to ensure transparency and fairness in their decision-making process. By analyzing the feature importance, the committee discovers that the top three factors driving loan rejections are low credit scores, insufficient income, and unstable employment status. Armed with this knowledge, they can communicate more effectively with loan applicants, provide guidance on how to improve their chances and avoid potential bias in the decision-making process.
Feature Selection
Knowing the importance of features can guide us in selecting the most relevant variables for training the model. It helps in reducing the dimensionality of the data and potentially improving the model’s efficiency and generalization.
Example:
Suppose you are working for a real estate agency that wants to build a machine-learning model to predict housing prices in a city. The agency has collected a dataset that includes various features for each property. The dataset is quite extensive, containing hundreds of features. But, including all the features might lead to overfitting, increased computational complexity, and difficulty in interpreting the model’s predictions. In other words, it is not that the more features, the better the result. It is time to use feature selection techniques to identify the most relevant variables for training the model.
With feature importance, the agency can identify a subset of the most relevant features that have the most significant impact on predicting housing prices. By reducing the dimensionality of the data and focusing on the most important variables, the model becomes more efficient, easier to interpret, and less prone to overfitting.
Data Understanding
Feature importance can provide insights into the underlying relationships and patterns present in the data. This knowledge can help domain experts gain a better understanding of the problem domain.
Example:
Suppose a car manufacturer built a machine learning model to predict fuel efficiency. After that, the manufacturer also wants to have a deeper understanding of how different features relate to fuel efficiency.
By analyzing feature importance, using visualization techniques like PDPs, and conducting correlation analysis, car manufacturers’ domain experts gain a better understanding of the factors influencing fuel efficiency in their vehicles. This data-driven knowledge can inform decision-making in various stages of the car design process. They can prioritize lightweight materials, optimize engine sizes, and explore new engine configurations to improve fuel efficiency in future car models.
Debugging and Improvement
Identifying important features can help in debugging the model’s performance and guide improvement efforts. If certain features are found to have low importance, we may investigate issues related to data quality or model training.
Example:
Suppose you’re a key member of an E-Commerce company, tasked with developing a cutting-edge machine learning model to predict customer churn. As the model is deployed into a real-world environment, you begin to notice some puzzling behavior, like unusual predictions and inconsistent importance rankings. To tackle these issues effectively, leveraging feature importance becomes crucial in the debugging process.
By delving into the feature importance scores, you can identify specific features with exceptionally low scores. These might prove irrelevant or noisy, consequently misleading the model into making inaccurate predictions. Identifying and filtering out these insignificant features will allow you to refine the model’s decision-making process, leading to more precise and reliable results.
Another potential source of the unexpected behavior lies in the model’s hyperparameter settings during the training phase. By utilizing the insights gained from the feature importance scores, you can fine-tune critical hyperparameters, like the number of trees in the Random Forest or the maximum depth of the trees. This optimization process holds the promise of enhancing the model’s overall performance and stability, allowing it to thrive in real-world scenarios.
In summary, leveraging feature importance is the key to unraveling the enigmatic behavior of the machine learning model.