On October 24, 2023, I had the pleasure of speaking at the GDG Nuremberg AI/ML event about large language models (LLMs) and Google’s latest product, BARD. I’d like to thank the organizers and the audience for a wonderful event.
In my speech, I covered the following main points:
- Discriminative models and generative models
- What are LLMs and how do they work?
- What are the benefits and limitations of LLMs?
- LLM Development (using API) and Traditional ML Development
- What is BARD?
1. Discriminative models and generative models
Discriminative model
People are more familiar with discriminative models, which are trained to predict a target variable based on a set of features. Discriminative models are often used for classification tasks. For example, a discriminative model can be trained to identify dogs and cats, or, to predict whether a customer is likely to churn based on their behaviours.
Discriminative models are trained using a variety of different machine learning algorithms, such as logistic regression, SVM, and decision trees. These algorithms work by learning a decision boundary that can best separate the training data points into their respective classes. Once the decision boundary has been learned, the model can then be used to predict the class label for new data points.

Generative Models
The Generative models, on the other hand, are trained to generate new contents. They learn the underlying patterns and distributions of data and then using that knowledge to create new data that is similar to the training data. Generative models can be used to generate realistic and coherent images and videos, a variety of text formats, and of course, translate languages.

2. Large Language Model
Large language models refer to large, general-purpose language models that can be pre-trained and then fine-tuned for specific purposes.
How large is large?
People may have different definition of large. But “large” has been used to describe BERT (110 million parameters) as well as GPT-3 (up to 175 billion parameters). Meanwhile, “large” can refer either to the number of parameters in the model, or sometimes the number of words in the dataset.
The PaLM and its use cases
In April 2022, Google released PaLM(Pathways Language Model). PaLM is trained on a massive dataset of text and code, which includes books, articles, code repositories, and other forms of text. It has over 540 billion parameters, which is more than any other LLM. PaLM has achieved a state-of-the-art performance across multiple language tasks.

PaLM is capable of a wide range of tasks, including:
- Generating text, translating languages, writing different kinds of creative content, and answering questions in an informative way.
- Performing tasks that require commonsense reasoning, such as understanding and responding to analogies and metaphors.
- Learning new tasks from scratch, without being explicitly programmed.
The beauty of Pre-trained and fine-tuned
The large language models are pre-trained on a massive dataset of text and code. The pre-training process allows the LLM to learn the patterns and relationships between words and phrases in the language. It also means that you don’t have to suffer the pain of handling complex engineering challenges or the cost of computing. You can just use it by calling API.
When you expect a more customised task, you also can fine-tune it on a dataset that is specific to your needs. Once you have fine-tuned the LLM, you can use it to generate text, translate languages, write different kinds of creative content, or get answers to questions about the topic that you trained it on.
3. What are the benefits and limitations of LLMs?
Benefits

Limitations
- Bias: LLMs are trained on massive datasets of text and code, which can reflect the biases that exist in the real world. This can lead to LLMs generating text that is biased or offensive.
- Hallucination: LLMs can sometimes generate text that is factually incorrect or misleading. This is because LLMs are trained to generate text that is similar to the training data, and the training data may contain incorrect or misleading information.
- Lack of explainability: LLMs are complex models, and it can be difficult to explain why they generate certain outputs. This can make it difficult to trust LLMs for critical tasks.
4. LLM Development (using API) and Traditional ML Development
Traditional machine learning development can be time-consuming and complex, requiring extensive data preprocessing, model training and optimization, and domain expertise. In contrast, LLM development is much simpler, thanks to the power of pre-training. LLMs have learned a vast amount of knowledge during pre-training, so they require fewer training examples and less domain knowledge. Instead, the focus is on prompt design and engineering, which involves creating clear, concise, and informative prompts.

5.What is BARD?
BARD is launched as an experiment in March 2023. It is an early experiment with generative AI.
It is still a baby but powerful.

The meaning of BARD in large language models is Bidirectional Auto-Regressive Decoder. It is a type of neural network model that is trained to predict the next word in a sequence, both forwards and backwards.
BARD uses the Pathways Language Model 2 (PaLM 2). It is the most advanced language model that Google has ever developed.
- It is trained on a dataset that is specifically designed to be informative and comprehensive. This means that BARD is better at generating text that is factually accurate and complete.
- It is trained using a technique called “Pathways Language Model” (PaLM), which allows it to learn the relationships between different concepts and ideas in a more comprehensive way. This means that BARD is better at understanding the context of a query and generating a response that is relevant and informative.
- It is trained using a technique called “Sparrow dialogue finetuning”, which allows it to learn how to have more natural and engaging conversations. This means that BARD is better at interacting with users in a way that is similar to how a human would.
BARD is very good at having natural and engaging conversations. For example, if you ask BARD to tell you a joke, BARD will be able to generate a joke that is funny and relevant to the conversation.
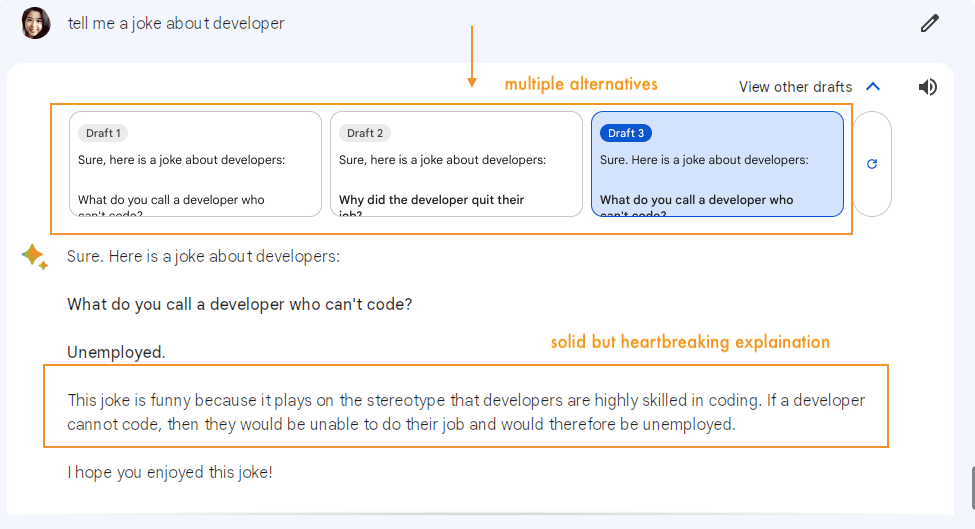
Well, to be honest, I’m regretful that I asked a joke. BARD knows too much and the answer is painful.
Overall, BARD is a powerful LLM that is designed to be informative, comprehensive, and engaging. It is a valuable tool for anyone who needs to generate text, translate languages, write different kinds of creative content, or get answers to questions.